GraphQL vs REST
GraphQL for REST Developers
Let's start by busting a myth: whatever you've heard, REST and GraphQL are not sworn enemies. You don't have to throw out all your REST stuff just because GraphQL is moving in. When it comes to sending data between client and server, REST and GraphQL are two tools in the same development box - and they have a lot more in common than you might think.
In this GraphQL primer for REST devs, we'll draw some parallels, explain some differences, and show you just how quickly you can get started.
Use what you know
First off - you can use the knowledge you have to build REST APIs and GraphQL APIs.
That's because both REST and GraphQL describe rules that we can follow to make requests from a client, and respond with data from a server. At the end of the day, we're still creating an agreement between client and server, much like a partnership or contract between two people. As with any good agreement, both parties should understand what they're getting out of it - AND what they need to do to hold up their end of the contract.
In software, we call this an application programming interface, or API, because it allows us to define and understand how two systems can interact: which buttons each can push on the other, which of their levers they can pull, and what kind of exchange of data can occur between them.
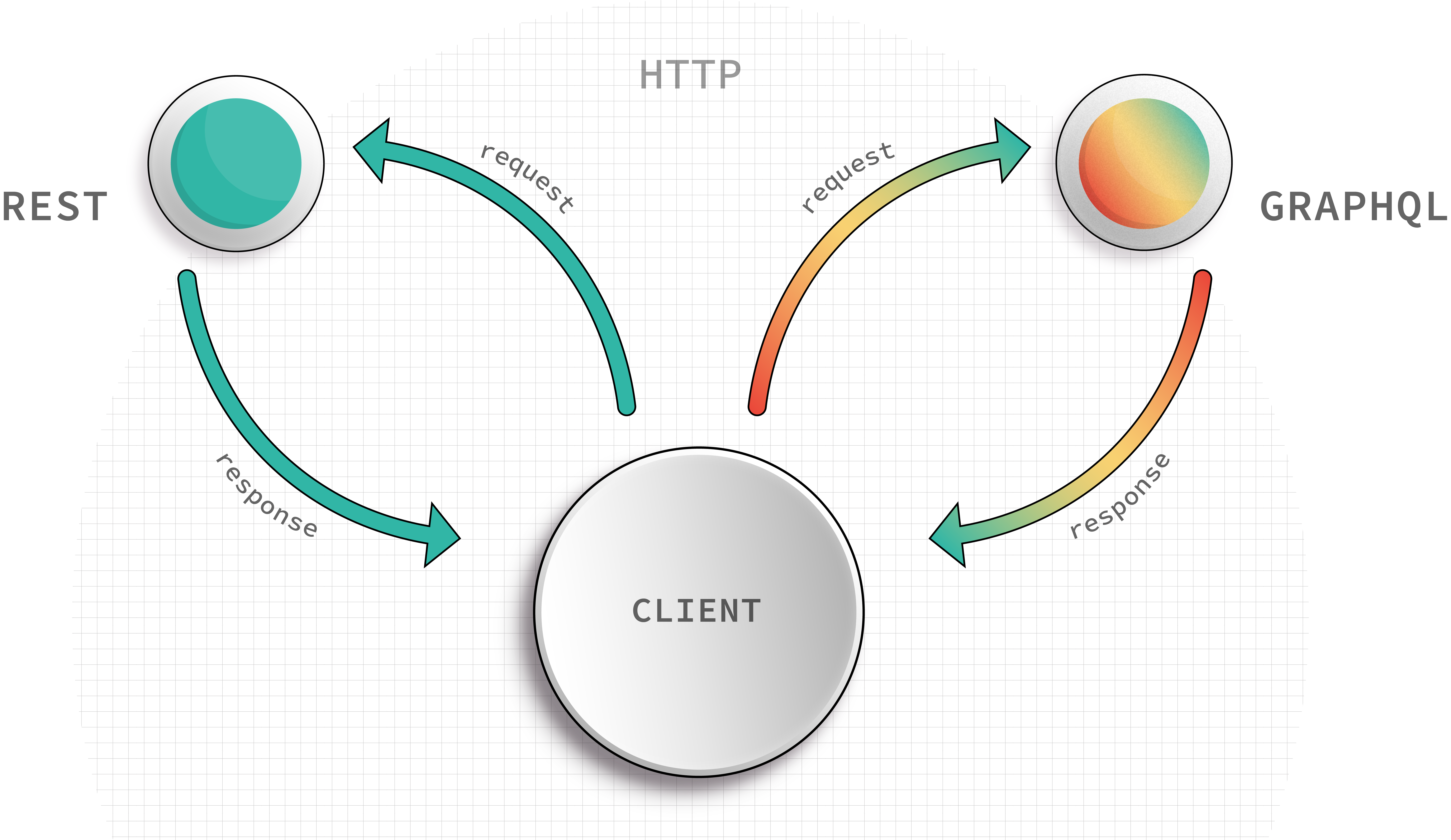
So, if you understand how to build and use REST APIs, the concepts stick when applied to GraphQL. GraphQL requests use the same HTTP protocol that REST does. There is still a client that sends requests, and a service that receives requests and sends responses. Your clients don't have to rework their entire codebase to work with GraphQL, and you don't need to drop your databases and start over. Perhaps most importantly, you don't need to toss out your REST APIs. GraphQL is flexible, and it can be adopted incrementally, which means you can keep your architecture, your data, and your REST APIs, and still see the benefits after even a small dose of GraphQL.
Leave some details at the door
When working with REST APIs, we have a number of verbs to choose from to help describe the kind of request we're submitting. With GraphQL, we have just two: query and mutation.
When we'd normally reach for GET with a REST API, we can use query with a GraphQL service.
For the rest of the verbs - POST, PUT, PATCH, and DELETE - we can lean on mutation for GraphQL operations that change data in some way. We don't have to clarify the why or the how - we can simply get to mutating!
Start where you are
To be clear, you don't need a REST API to jump into GraphQL - but it's a good way to witness one of GraphQL's greatest strengths: the ability to access lots of different data sources to satisfy a single request. This means that you can place a GraphQL layer up in front of your REST APIs and witness how a single, organized query can be resolved with data from multiple resources at once.
Even with a single REST API to work with, we can gradually test the power of GraphQL. Its ability to consume data from different data sources means that a GraphQL service can just as easily request - and then return - data from a REST API directly.
In practice, this means that we start by sending requests to the GraphQL service, which hands them over to the REST API. The REST API gets the data we asked for, and passes it back to the GraphQL service. Then, it sends our data back to us.
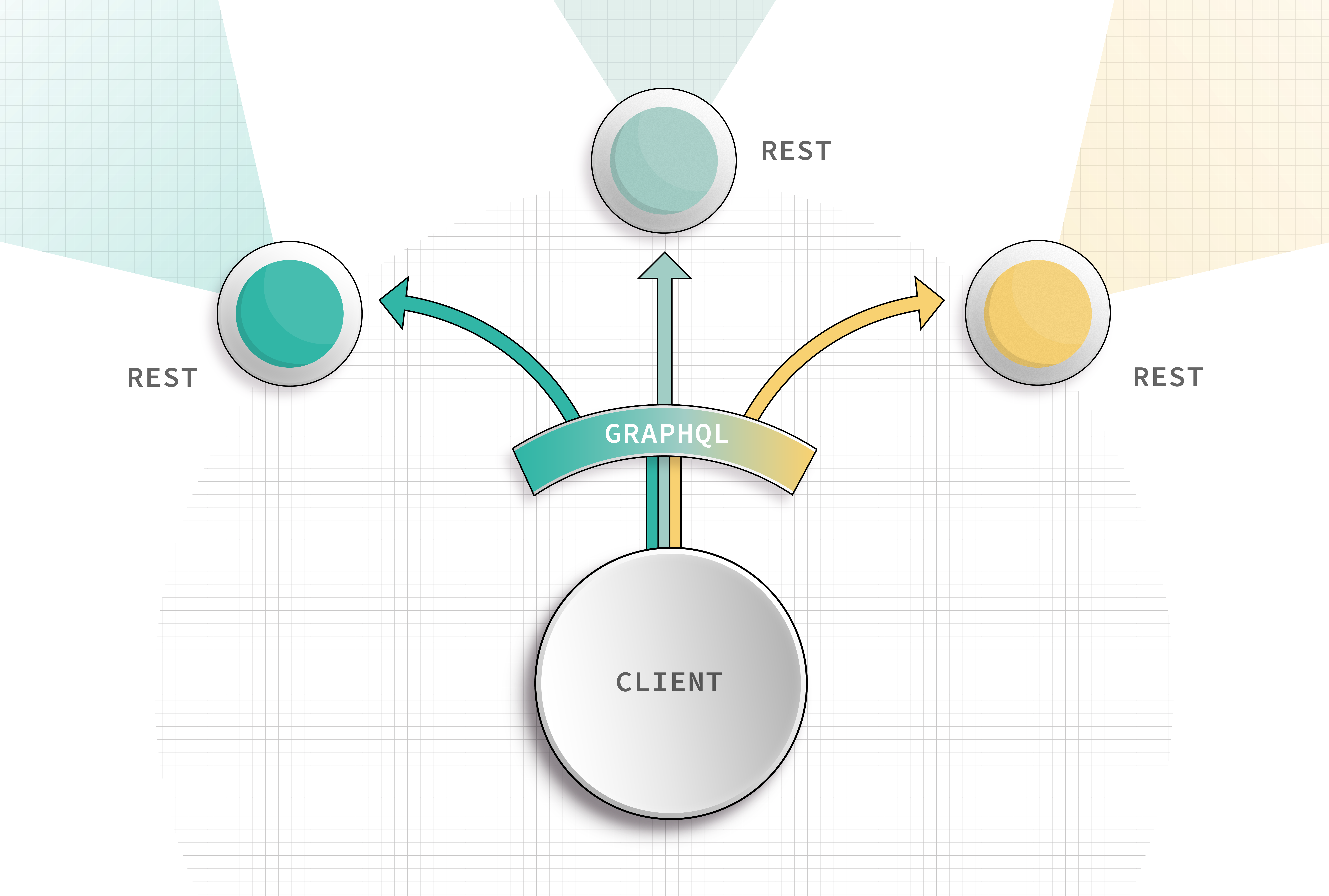
So what's the big deal? We've added another stop along the way between our request and our response, and it doesn't look like we've gained a ton.
Well, there's more here than meets the eye. By passing through the GraphQL service, we now have a greater degree of control about which pieces of the request end up reaching the REST API. This means that we can incrementally pluck off fields that the REST API used to be responsible for and let the GraphQL service fulfill them instead!
It's able to do this by setting up a data source. Rather than always having to pass the request through the REST API, the GraphQL service can talk to the backing database directly! It's like building a new road for traffic to flow through - we can create a new pathway that lets us control with greater precision how our requests are resolved, and where the data comes from.
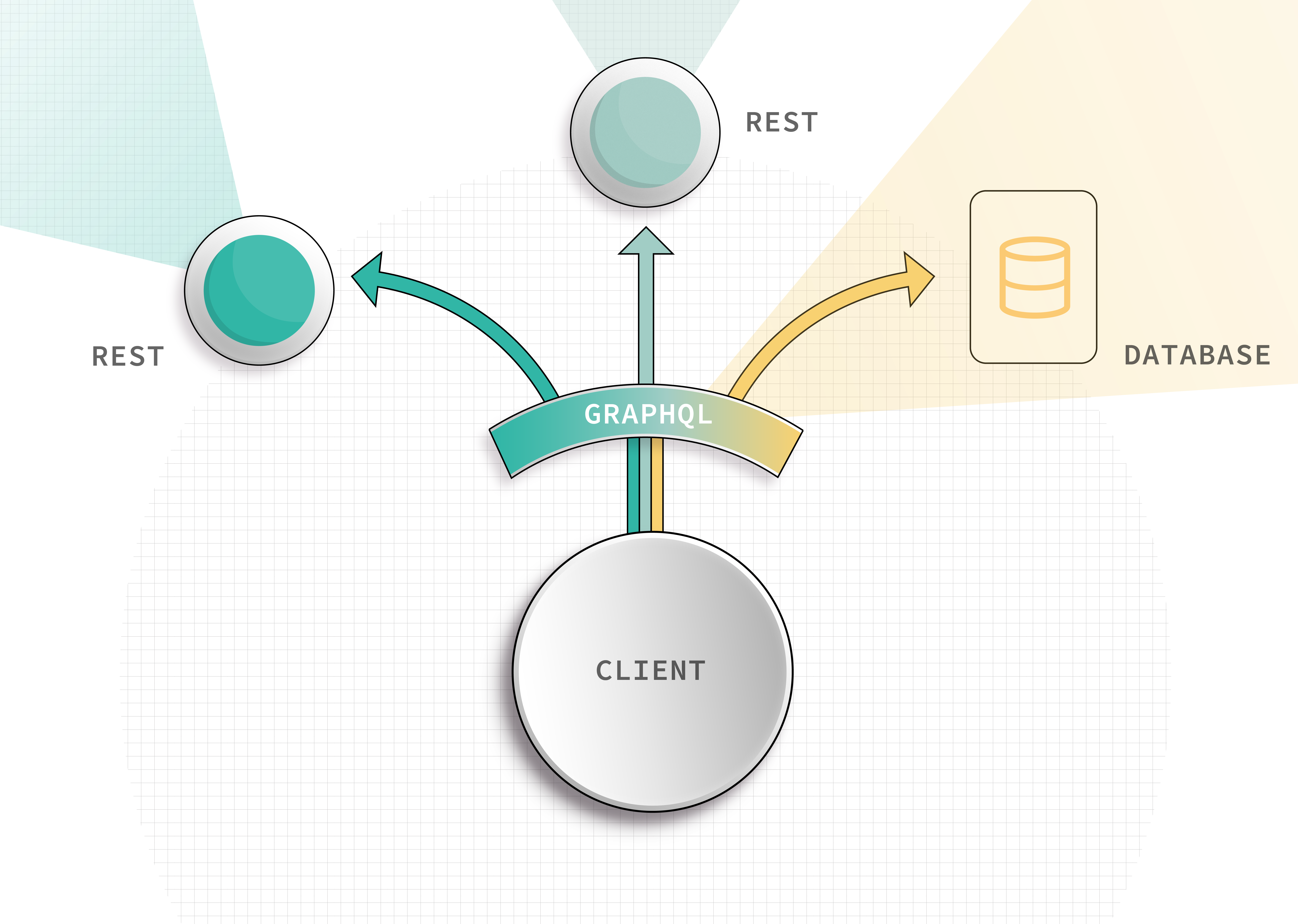
Though this models how easily and incrementally GraphQL can be adopted, it in no way means that you need to throw away your REST APIs in favor of re-implementing all of the data logic in a GraphQL service. Instead, visualize the power of a single service that can reach out, simultaneously, to multiple data sources - REST APIs included! - to satisfy a single query with many different fields. The power of GraphQL is yours to play with, whatever your API needs!
Taken further, GraphQL reveals the magic it brings to building API gateways, whether your architecture leans more toward microservices or monolith. A central GraphQL layer lets you create one map of all of the accessible data and resources your system can serve up, while still hiding how you've implemented everything. This creates a single point of entry for all of your requests, and a common interface that can be shared with all of your clients clamoring for some data.
And this definitely makes the frontend happy. That's because GraphQL queries are clean and clear, and they don't care at all about what data is stored where, or how resources are accessed: they just state what they need and wait for the result.
A GraphQL layer that sits between your client and your services can receive a request, determine what data it requires, and call out to the resources that fulfill it. To make this possible, the resource that returns data - for instance, a REST API - is broken down into terms of the types and fields it provides. These are defined in the GraphQL service's schema. The schema is a document that holds all of the definitions for the types of data a client might want to know about, and the specific details they can ask for, and it builds a map that any query can use to ask for whatever it wants.
What does a schema look like?The backend benefits
This is great for frontend devs, you might be thinking, but what do we get out of it? Not to worry! We're back to the contract we talked about earlier: there's something for everyone when GraphQL is the API of choice.
Indeed, GraphQL does make requesting data much easier. Even if a query needs to ping ten different data sources to gather up everything a request wants, it's still just a single query on the frontend that can get the job done. But the declarative, human-readable query isn't just nice to look at - its structure comes from the super powerful and descriptive schema, which is functional as well as self-documenting. This means that to understand how to query for something specific, all anyone writing a query needs to do is look at the schema that powers it! The hierarchical, strongly-typed format of the schema creates a consistency that both the backend and frontend can rely upon as a source of truth for how requests are sent and fulfilled.
With self-documenting schemas, there's a lot of time NOT spent discussing design particulars, parameters, and pathways. How you wire up the backend is no longer the concern of the people requesting the data! Client-side devs can work with a happy and flexible interface that exposes all of the necessary details to request data, not the nuts, bolts, and pipes that deliver it.
And that interface isn't brittle, either. If you add a type or a new field to the schema, nothing breaks. The client can start including it in their queries, or leave it for later.
The process for removing fields is just as flexible: GraphQL comes with a mechanism to mark a field or type as deprecated, and you can provide instructions so that the people making requests know what to use instead. And because clients select the individual fields they want to query, we can see exactly which deprecated fields are still in use. With that kind of insight, we're able to determine exactly when it's safe to remove deprecated functionality.
Instead of building new endpoints - or duplicating existing endpoints, but with minor variations - you add types and fields to the schema. Picking and choosing just the pieces they need from this menu, clients can define their own requests and tweak or configure them at a moment's notice. This added flexibility for client developers allows you to focus on forging the pathways to the data with GraphQL's resolver functions.
A GraphQL service needs resolver functions to understand how to retrieve the data for each field in a query. Whether you write resolver functions for each field in your schema, or even just for each type, you only have to write them once. Then no matter the request that comes the way of your GraphQL layer, it can be fulfilled by a combination of resolver functions that understand just how to fetch the data they're responsible for.
When you have a central GraphQL layer that receives all of your client requests - whether those clients are laptops, tablets, mobile phones, or even refrigerators - you begin to see that the way you're able to provide data is super adaptable. Resolver functions open the door to green fields, where you can use a variety of data sources. One function could call a REST endpoint for data; another could query a database directly. A third could be a total oddball, and do something completely different! The GraphQL layer works as a hub for the traffic of your requests to run through, but it doesn't bake in the rules for how you resolve them. That's up to you!
GraphQL for the REST of us
GraphQL vs REST? Not exactly. GraphQL hasn't arrived to turn the world upside down, or put REST out on the curb. It's a tool that we can reach for when we're ready; when we have a new problem, or one too many endpoints; when our development process has gotten brittle, or bogged down on API requirements and design. It's flexible enough for us to sample, and strong enough to scale - and now, it even has GraphOS, an end-to-end platform to supercharge the way we build, test, and ship the graphs that power tomorrow's data.
Want to see how it all works?
- Learn GraphQL, starting with the basics
- Odyssey's Lift-off II: Resolvers tutorial walks you through how to use a REST API as a datasource for a GraphQL server.
- Looking for a video explainer for what GraphQL is? Check it out!
Up Next: Top GraphQL Tools
About
GraphQL.com is maintained by the Apollo team. Our goal is to give developers and technical leaders the tools they need to understand and adopt GraphQL.
GraphQL.com 2026